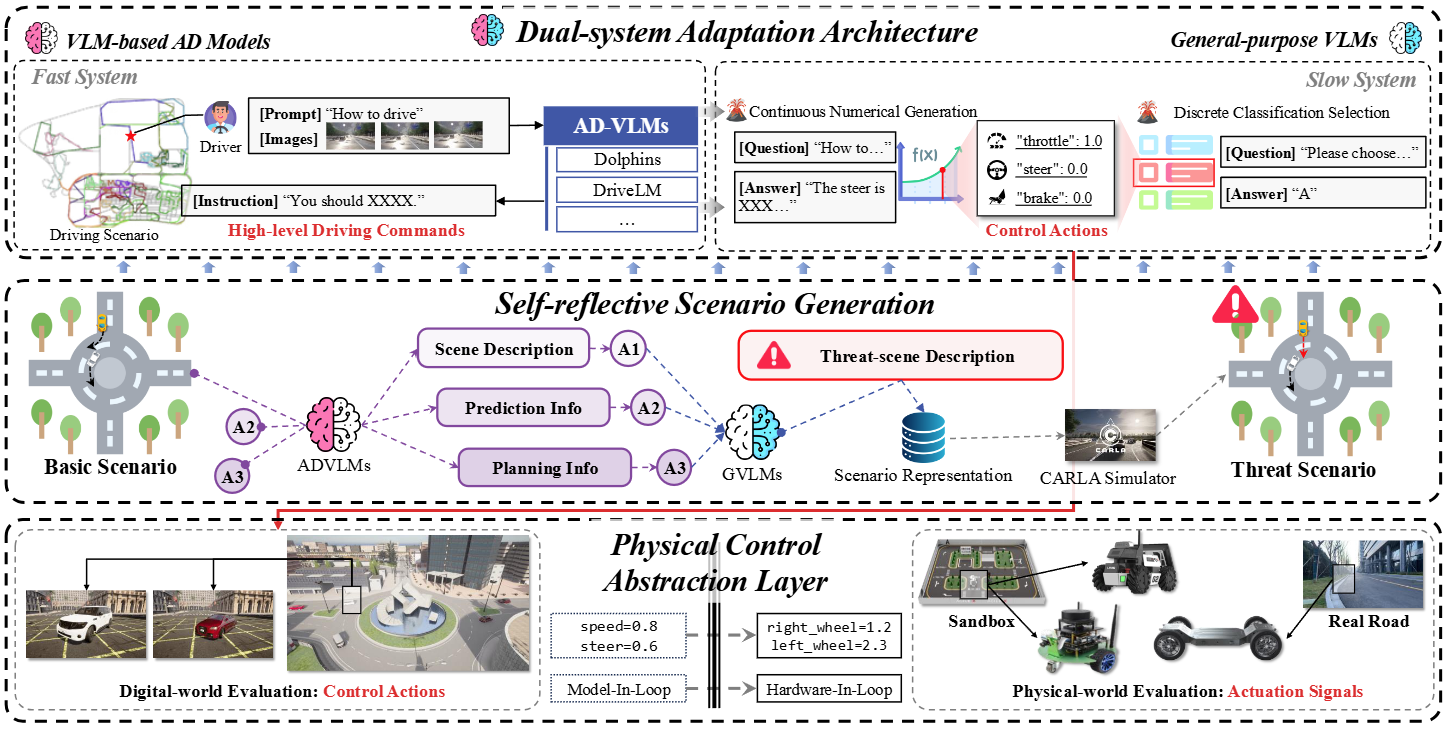
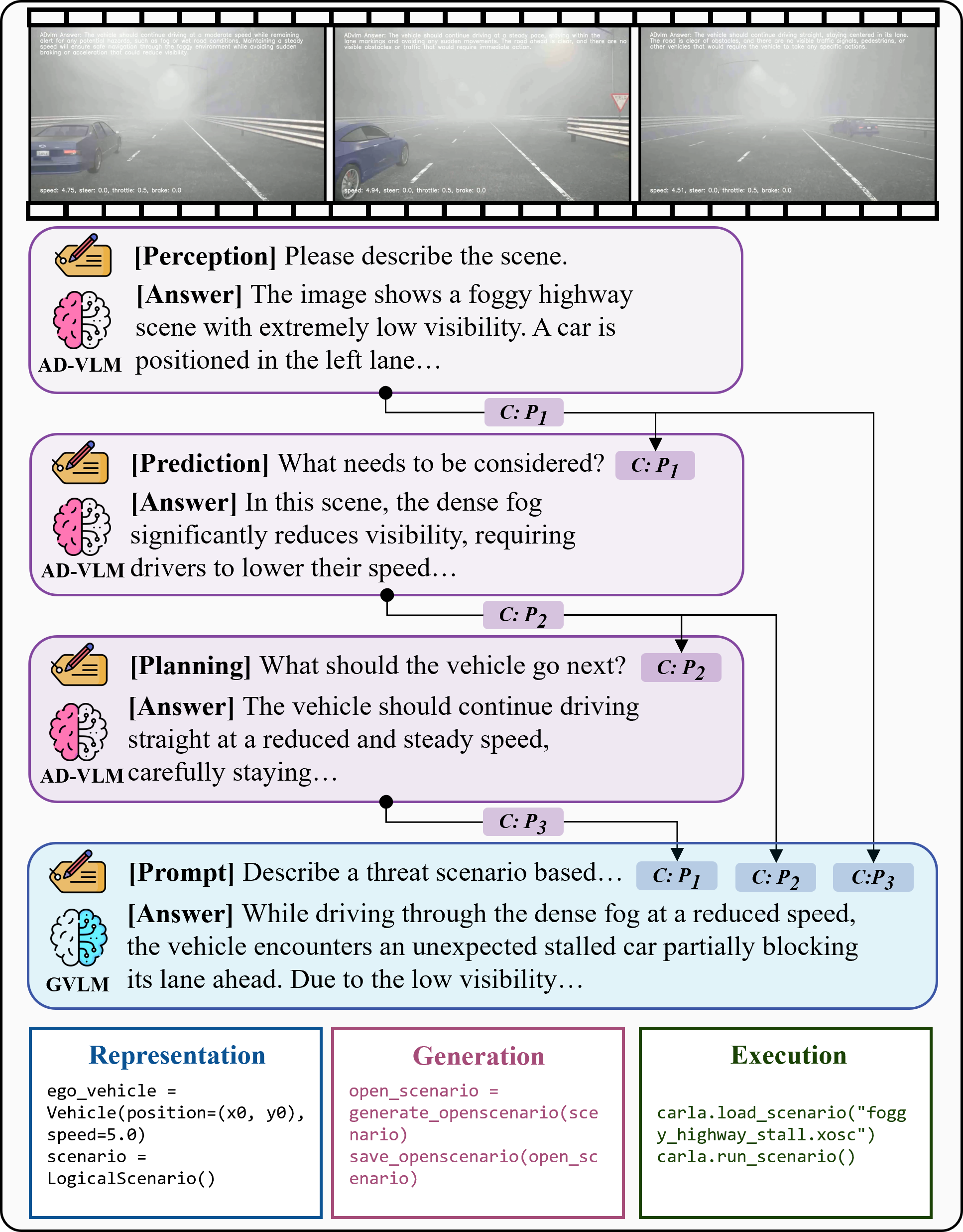
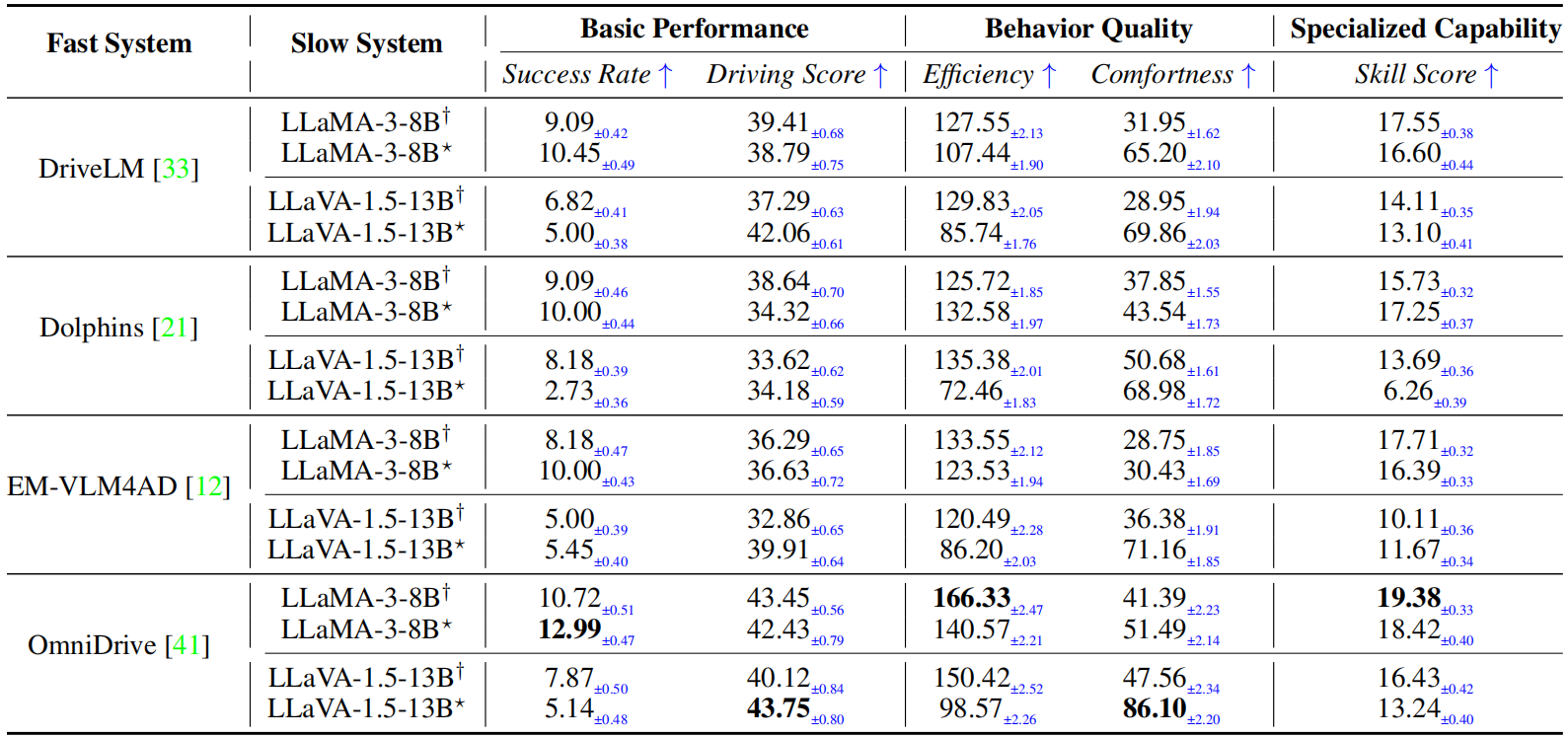
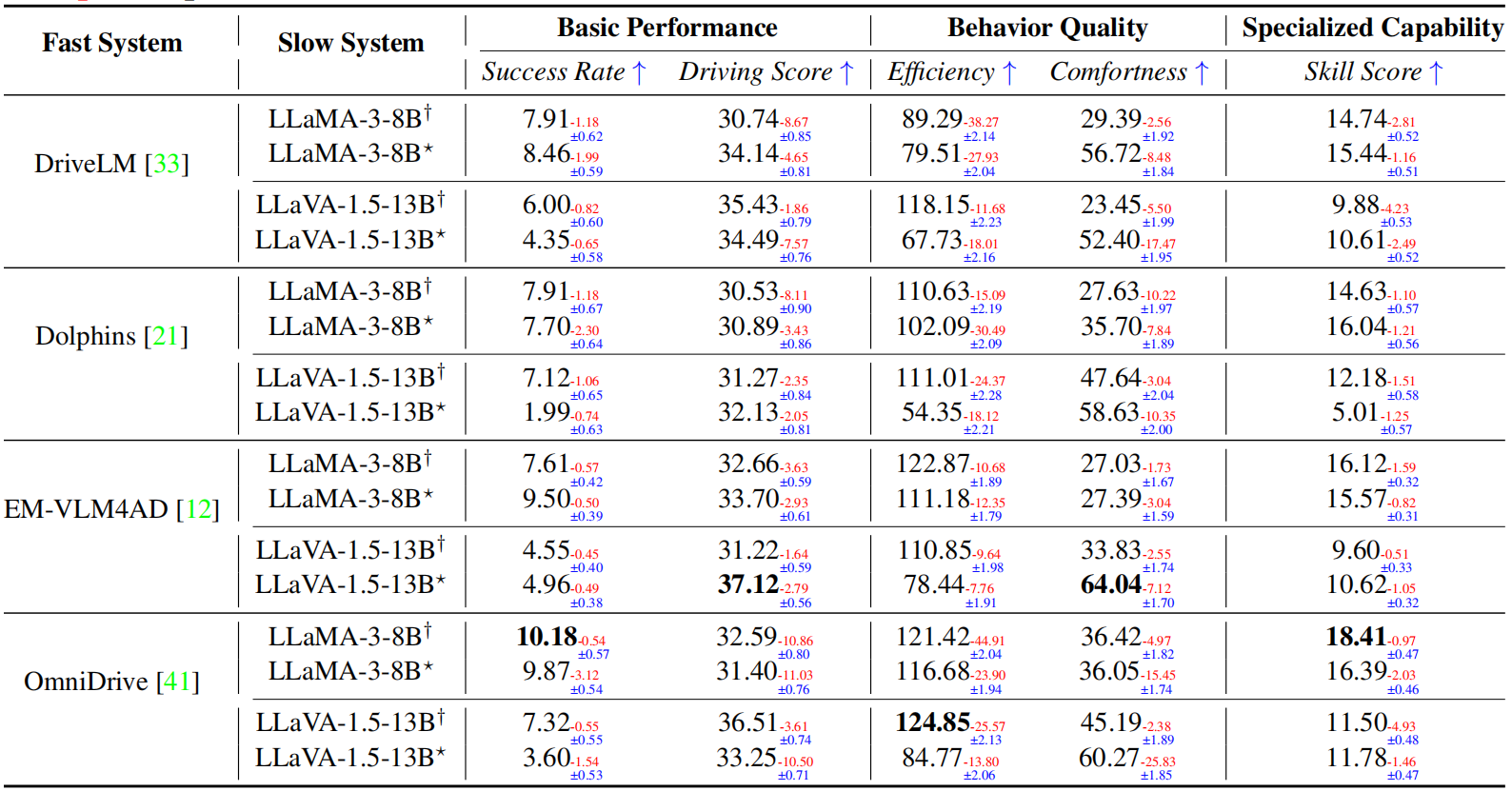
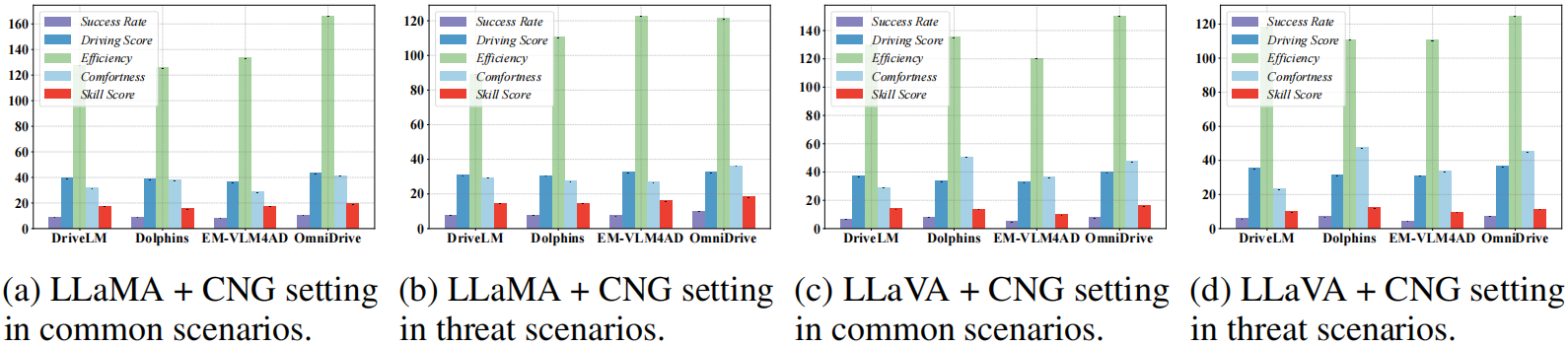
Vision-Language Models (VLMs) have recently emerged as a promising paradigm in autonomous driving (AD). However, current performance evaluation protocols for VLM-based AD systems (ADVLMs) are predominantly confined to open-loop settings with static inputs, neglecting the more realistic and informative closed-loop setting that captures interactive behavior, feedback resilience, and real-world safety. To address this, we introduce Bench2ADVLM, a unified hierarchical closed-loop evaluation framework for real-time, interactive assessment of ADVLMs across simulation platforms. Inspired by dual-process theories of cognition, we first adapt diverse ADVLMs to simulation environments via a dual-system adaptation architecture. In this design, heterogeneous high-level driving commands generated by target ADVLMs (fast system) are interpreted by a general-purpose VLM (slow system) into standardized control actions suitable for execution in simulation. To enable more comprehensive evaluation, Bench2ADVLM introduces a self-reflective scenario generation module that automatically explores model behavior and uncovers potential failure modes for safety-critical scenario generation, constructing a benchmark including 220 common routes and 220 threat scenarios. Experiments across 4 state-of-the-art ADVLMs and 16 different combinations validate the diagnostic strength of our framework, revealing that existing ADVLMs still exhibit limited performance under closed-loop conditions. Furthermore, we design a physical control abstraction layer that translates simulation actions into actuation signals, enabling closed-loop evaluation of ADVLMs on 3 physical vehicles. Bench2ADVLM is flexible and extensible, supporting diverse VLMs and enabling deployment across heterogeneous vehicles. To our knowledge, this is the first work to establish the closed-loop evaluation framework for ADVLMs, offering a principled path toward scalable, reliable deployment of ADVLMs.